أطلقت شركة جوجل ديب مايند (Google DeepMind) الجيل الجديد من نموذجها العالي القدرة للذكاء الاصطناعي، جيميني (Gemini)، الذي يتمتع بإمكانات أكبر من حيث القدرة على التعامل مع مقادير كبيرة من مقاطع الفيديو والنصوص والصور.
جيميني 1.5 برو
يمثل هذا النموذج تطوراً ملحوظاً بالمقارنة مع الإصدارات الثلاث السابقة من جيميني 1.0 (Gemini 1.0) التي أعلنت عنها جوجل في ديسمبر/كانون الأول؛ والتي تتسم بدرجات متزايدة من الحجم والتعقيد من إصدار نانو (Nano) وصولاً إلى برو (Pro) وانتهاء بألترا (Ultra). من الجدير بالذكر أن جوجل أطلقت جيميني 1.0 برو وجيميني 1.0 ألترا في العديد من منتجاتها مؤخراً. أما الآن، فسوف تطلق جوجل نسخة أولية من جيميني 1.5 برو (Gemini 1.5 Pro) لمجموعة مختارة من المطورين والعملاء التجاريين. تقول الشركة إن جيميني 1.5 برو؛ الذي يعد المستوى المتوسط للنموذج الحالي، يضاهي نموذجها السابق من المستوى الأعلى جيميني 1.0 ألترا من حيث الأداء؛ لكنه يحتاج إلى مستوى أقل من الإمكانات الحاسوبية (أجل، هذه الأسماء مثيرة للارتباك).
أما الأهم من ذلك فهو أن جيميني 1.5 برو قادر على التعامل مع كميات أكبر بكثير من البيانات التي يقدمها له المستخدمون؛ بما فيها حجم الأوامر النصية. ثمة حد أقصى لمقدار البيانات التي يستطيع كل نموذج ذكاء اصطناعي معالجتها؛ غير أن النسخة القياسية من جيميني 1.5 برو الجديدة تستطيع التعامل مع مدخلات يصل حجمها إلى 128,000 رمز مميز (token)؛ أي الكلمات أو أجزاء الكلمات الناتجة بعد تفكيك نموذج الذكاء الاصطناعي للمدخلات. يضاهي هذا الأداء أداء أفضل نسخة من جي بي تي 4 (GPT-4)، أي جي بي تي 4 توربو (GPT-4 Turbo).
اقرأ أيضاً: إليك ما يجب أن تعرفه عن جيميني: نموذج الذكاء الاصطناعي الجديد من جوجل
تلقيم جيميني 1.5 برو بما يصل إلى مليون رمز
لكن الشركة ستتيح لمجموعة محدودة من المطورين تلقيم جيميني 1.5 برو بما يصل إلى مليون رمز؛ ما يكافئ تقريباً مقطع فيديو بطول ساعة واحدة، أو مقطعاً صوتياً بطول 11 ساعة، أو مقطعاً نصياً بطول 700,000 كلمة. يمثل هذا المقدار قفزة كبيرة تتيح إنجاز مهام لا يستطيع أي نموذج آخر إنجازها حالياً.
ففي أحد مقاطع الفيديو التجريبية التي عرضتها جوجل، وباستخدام الإصدار القادر على معالجة مليون رمز، لقم الباحثون النموذج بنص بلغ طوله 402 صفحة حول بعثة أبولو التي هبطت على القمر. وبعد ذلك، عرض الباحثون على جيميني رسماً أولياً يدوياً لحذاء له ساق طويلة، وطلبوا منه أن يحدد اللحظة المتوافقة مع هذا الرسم في النص.
قدم بوت الدردشة إجابة صحيحة، قائلاً: “هذه هي اللحظة التي هبط فيها نيل أرمسترونغ على سطح القمر. وقال حينها: هذه خطوة واحدة صغيرة بالنسبة إلى شخص واحد؛ لكنها قفزة عملاقة بالنسبة إلى البشرية”.
تمكن النموذج أيضاً من تحديد اللحظات المضحكة. فعندما طلب منه الباحثون أن يعثر على لحظة مضحكة في نص بعثة أبولو، اختار اللحظة التي أشار فيها رائد الفضاء مايك كولينز إلى أرمسترونغ باسم “القيصر”. (قد لا يكون اختياراً موفقاً، لكنه مُبَرر على أي حال).
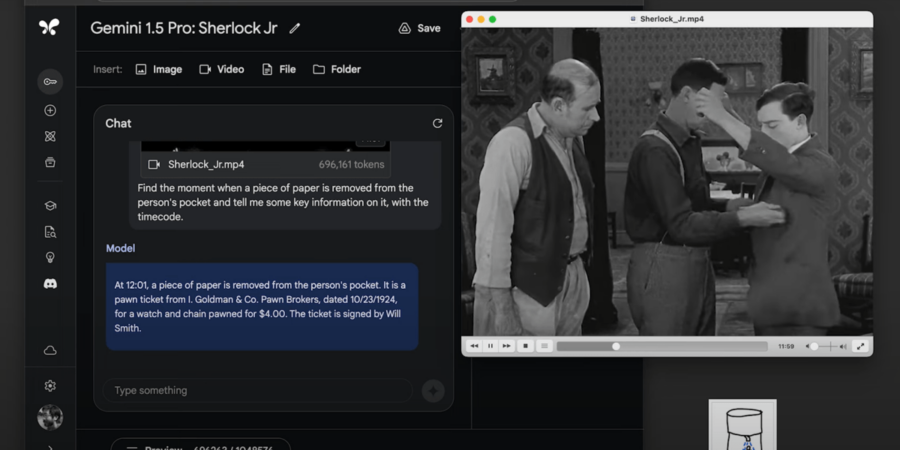
في عرض تجريبي آخر، لقم الفريق نظام الذكاء الاصطناعي بفيلم صامت بطول 44 دقيقة من بطولة باستر كيتون، وطلبوا من النظام تحديد المعلومات المكتوبة على قطعة من الورق كانت في جيب إحدى الشخصيات في إحدى مراحل الفيلم، وأُخرِجت منه لاحقاً. خلال أقل من دقيقة، وجد النموذج الملف المطلوب، واستذكر النص المكتوب على الورقة من دون أخطاء. كرر الباحثون مهمة مماثلة أيضاً من تجربة بعثة أبولو؛ حيث طلبوا من النموذج أن يعثر على مشهد في الفيلم بناء على رسم، وقد أنجز المهمة بالكامل.
تقول جوجل إنها طبقت على جيميني 1.5 برو مجموعتها القياسية من الاختبارات التي تستخدمها عند تطوير النماذج اللغوية الكبيرة؛ بما فيها اختبارات التقييم التي تجمع بين النص والرموز البرمجية والصور والصوت والفيديو. ووجدت أن 1.5 برو يتفوق في الأداء على 1.0 برو في 87% من المعايير، ويضاهي 1.0 ألترا على وجه التقريب في جميع المعايير مع الاعتماد على مستوى أقل من القدرات الحاسوبية.
اقرأ أيضاً: كيف يمكنك استخدام جيميني من جوجل بطريقة تزيد إنتاجيتك؟
قدرة جيميني 1.5 برو على التعامل مع مدخلات أكبر
تقول جوجل إن القدرة على التعامل مع مدخلات أكبر تُعزى إلى التقدم الذي أحرزته في المجال الذي تطلق عليه اسم ” البنية المتعددة الخبرات”. ويستطيع نظام الذكاء الاصطناعي الذي يعتمد على هذا التصميم تقسيم شبكته العصبونية إلى أجزاء مختلفة؛ حيث يفعّل الأجزاء المتعلقة بالمهمة المطلوبة منه وحسب، بدلاً من تشغيل الشبكة العصبونية بأكملها في الوقت نفسه. من الجدير بالذكر أن استخدام هذه البنية لا يقتصر على جوجل، فقد أطلقت شركة الذكاء الاصطناعي ميسترال (Mistral) نموذجاً يعمل وفق هذه البنية، كما أن الإشاعات تقول إن جي بي تي 4 يعتمد عليها أيضاً.
يقول أحد قادة فرق التعلم العميق في ديب مايند، أوريول فينيالس: “يمكن تشبيه طريقة عمل هذا النموذج، وفق وجهة نظر معينة، بطريقة عمل أدمغتنا؛ حيث لا ينشط الدماغ بأكمله طوال الوقت”. يوفر هذا الأسلوب في التقسيم القدرات الحاسوبية المطلوبة للعمل، ويساعد على توليد الإجابات بسرعة أكبر.
يقول المدير التقني السابق لمعهد آلين (Allen) للذكاء الاصطناعي، أورين إتزيوني، الذي لم يشارك في العمل: “هذا النوع من المرونة في الانتقال جيئة وذهاباً بين الوسائط المختلفة، واستخدام هذه الميزة في البحث والفهم، أمر مثير للإعجاب فعلاً. لم أرَ شيئاً مماثلاً من قبل”.
يمثل الذكاء الاصطناعي القادر على العمل عبر وسائط مختلفة نموذجاً أقرب إلى سلوك البشر. يقول إتزيوني: “يميل البشر بطبيعتهم إلى الاعتماد على وسائط عدة مختلفة”؛ حيث نستطيع الانتقال بسلاسة بين الكلام والكتابة ورسم الصور أو الأشكال البيانية من أجل التعبير عن أفكارنا.
غير أن إتزيوني يحذر من المبالغة في التفاؤل إزاء هذه التطورات. ويقول: “ثمة عبارة شهيرة تقول: إياك أن تثق بعرض تجريبي لذكاء اصطناعي”.
اقرأ أيضاً: كيف يمكنك تجربة جوجل جيميني بسهولة؟
فمن ناحية، ليس من الممكن تحديد ماهية الأشياء التي لم تُعرض في مقاطع الفيديو، أو مدى الانتقائية في اختيار المهام التي عُرِضت فيها، ومن الجدير بالذكر إن جوجل تعرضت إلى الانتقاد بعد إطلاق جيميني سابقاً لأنها لم تذكر أن مقاطع الفيديو كانت مُسَرعة. كما أنه من المحتمل أن النموذج لن يتمكن من إعطاء النتائج التي ظهرت في العروض التجريبية عند تطبيق تعديلات طفيفة على صياغة الأوامر النصية. يقول إتزيوني إن نماذج الذكاء الاصطناعي حساسة للغاية عموماً.
يقتصر التعامل مع إصدار جيميني 1.5 برو حالياً على المطورين والعملاء من الشركات. ولم تحدد جوجل موعد إطلاقه على نطاق واسع.