
لطالما كان توليد الكلام آلياً تقنية مخيبة للآمال في بعض نواحيها، فحتى أفضل نُظُم تحويل النصوص إلى كلام تعاني من الطابع الميكانيكي للصوت المُنتَج، وتفتقر إلى العلامات الأساسية للتنغيم (ارتِفاع الصَّوت وانخفاضه) التي يستخدمها البشر عندما يتحدثون. وذلك مثل نظام الكلام الواسع الانتشار الذي استخدمه ستيفن هوكينغ.
وهذا مستغرب إلى حدٍّ ما نظراً للتقدم الهائل الذي أحرزه حقل "التعلم الآلي" في السنوات القليلة الماضية. وسيظن القارئ لأول وهلة أن التقنيات التي برعت تماماً في التعرّف على الوجوه والأغراض ومن ثَم تمكنت من إنتاج صور واقعية لها، قادرة أيضاً على فعل هذا مع الصوت. لكن هذا ليس صحيحاً.
أو بصورة أدقّ: لم يكن ذلك صحيحاً حتى اليوم؛ حيث تمكّن شون فاسكيز ومايك لويس، الباحثان لدى مختبر بحوث الذكاء الاصطناعي التابع لفيسبوك، من اكتشاف طريقةٍ لتجاوز العقبات التي تعترض نُظُم تحويل النصوص إلى كلام، ونجحوا في إنتاج مقاطع صوتية قريبة من الواقع بشكل لافت للنظر، مُولَّدة كلياً بواسطة الآلة.
وهذه الآلة التي طوروها -المسماة مِل نت (MelNet)- لا تكتفي بنسخ التنغيم البشري فحسب، بل تستطيع إنتاجه بشكلٍ يحاكي أصوات الأشخاص الحقيقيين. وهكذا قام فريق البحث بتدريب هذا النظام على التحدث مثل بيل جيتس، وغيره من الشخصيات. وتفتح هذه الدراسة الباب أمام إمكانية حدوث تفاعل أكثر واقعية بين البشر وأجهزة الحاسوب، وفي الوقت ذاته تُثير المخاوف من نشوء طوفان رقميّ من المحتوى الصوتي المزيَّف. ولنبدأ بذكر بعض المعلومات الأساسية.
إن سبب البطء الملاحظ في تقدم تطوير نُظُم واقعية لتحويل النص إلى كلام لا يعود إلى قلة المحاولات البحثية لفعل ذلك؛ بل إن عدداً كبيراً من الفِرَق حاول بالفعل تدريب خوارزميات التعلم العميق على إنتاج كلام واقعيّ مستخدمين قواعد بيانات ضخمة من الملفات الصوتية.
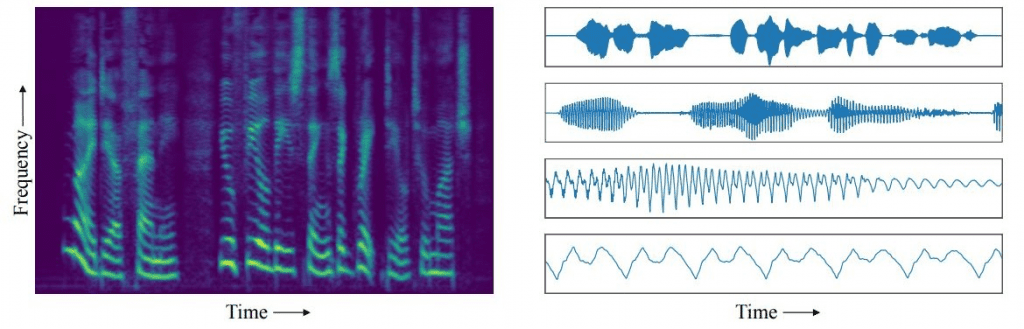
لكن المشكلة في تلك المقاربة -كما يشير الباحثان فاسكيز ولويس- يكمن في نوع البيانات المستخدمة في التدريب؛ حيث إن معظم تلك المحاولات قد ركزت حتى الآن على التسجيلات التي تحفظ الصوت بشكل موجات، وذلك النوع من التسجيلات يُظهر كيف تتغير سعة موجة الصوت بمرور الزمن، حيث تتكون كل ثانية في المقطع الصوتي المسجَّل من عشرات الآلاف من النقاط الزمنية.
وإذا ما درسنا هذه الموجات، على نقاط مختلفة من السلّم الزمني، تُظهر لنا أنماطاً مميزة. على سبيل المثال، نلاحظ خلال الثواني الأولى من المقطع الصوتي، أن شكل الموجات يعكس الأنماط المميزة المتعلقة بتسلسل الكلمات. لكن على مقياس الميكروثانية (جُزء مِن مليون من الثانية)، تُظهر الموجات الخصائصً المميزة المتعلقة بطبقة الصوت وطابعه. أما على مقاييس زمنية أخرى، فتعكس الموجات النغمةً الكلامية للمتحدث، وبنية الفونيم في نطقه وما إلى ذلك.
وهناك طريقة أخرى لمقاربة هذه الأنماط تتمثل في النظر إليها على أنها ارتباطات ما بين الموجة في نقطة زمنية معينة والموجة في النقطة التي تليها. وعلى سبيل المثال -ووفق مقياس زمنيّ محدد- فإن الصوت في بداية إحدى الكلمات يرتبط بالأصوات التي تليه.
وبهذا الصدد، ينبغي على نُظُم التعلم العميق أن تُجيد دراسة هذه الأنواع من الارتباطات، وتُتقن إعادة إنتاجها. لكن المشكلة تكمن في أن هذه الارتباطات توجد على عدة مقاييس زمنية مختلفة، ونُظُم التعلم العميق لا تستطيع دراسة الارتباطات إلا على مقاييس زمنية محدودة، ويتمثل سبب محدوديتها في نوع من "عمليات التعلم" تنتهجه هذه النُظُم يُدعى "الانتشار الخلفي"؛ حيث تقوم هذه الخوارزمية مراراً وتكراراً بتغذية الشبكة العصبية لتحسين أدائها وفق الأمثلة التي تتدرّب عليها.
ومعدّل هذا التكرار هو الذي يحدُّ من المقياس الزمني الذي تتوزع عليه الارتباطات المُراد من الآلة دراستها. وهكذا ندرك أن شبكة التعلم العميق قادرة على دراسة الارتباطات في مقطع صوتي مسجّل بشكل موجات على مقياس زمني طويل أو قصير، لكن ليس الاثنين معاً في ذات الوقت؛ وهذا هو السبب الذي يجعل شبكات التعلم العميق ذات أداء سيئ جداً في إنتاج الكلام المسموع.
غير أن الباحثَين فاسكيز ولويس لديهما مقاربة مختلفة لتحسين الأداء؛ حيث استخدما المخططات الطيفية للمقاطع الصوتية لتدريب شبكتهما للتعلم العميق، بدلاً من المقاطع الصوتية المسجلة بشكل موجات. والمخططات الطيفية تسجّل كامل طيف ترددات الصوت وكيفية تغيرها بمرور الزمن، ولذلك فهي تلتقط التغيرات على نطاق كبير جداً من الترددات المختلفة، في حين لا يلتقط التسجيل الصوتي بشكل موجات إلا تغيُّر أحد البارامترات فقط، وهو "سعة الموجة" على مرّ الزمن.
هذا يعني أن معلومات المقطع الصوتي مُكدَّسة بشكل أكثر كثافة داخل المخططات الطيفية مقارنةً بالنوع الآخر من تمثيل البيانات، وهو: الشكل الموجيّ. وبهذا الصدد يقول الباحثان: "إن المحور الزمني للمخطط الطيفي أكثر تَراصّاً بالنسبة للحجم من المحور الزمني للشكل الموجي، مما يعني أن المتغيرات التابعة التي تتوزع على عشرات الآلاف من النقاط الزمنية في الشكل الموجي لا تمتد إلا على مئات النقاط الزمنية في المخطط الطيفي".
وهذا ما يجعل الارتباطات أسهل تناولاً لنُظُم التعلم العميق. ويشرح الباحثان ذلك بقولهما "إن استخدام المخططات الطيفية للمقاطع الصوتية يتيح لنماذجنا أن تولِّد عينات من الكلام والموسيقى دون ضرورة التقيّد بمقياس زمنيّ محدد".
أما النتائج التي توصلوا إليها فهي لافتة للانتباه حقاً؛ فبعد تدريب النظام على المقاطع الصوتية الطبيعية من محاضرات تيد (TED talks)، تمكّن مِل نت (MelNet) من إعادة إنتاج صوت أحد المتحدثين في تيد بحيث يمكنك إنطاقه بأي شيء تريد لبضعة ثوانٍ. وبهذا أثبت الباحثون التابعون لشركة فيسبوك مرونةَ النظام باستخدام محاضرة بيل جيتس في "تيد" من أجل تدريب مِل نت (MelNet)، ومن ثَم استخدموا الصوت المُنتج لنُطق مجموعة متنوعة من العبارات العشوائية.
إليكم هذا النظام وهو ينطق جملة “We frown when events take a bad turn" (لم يعجبنا الأمر عندما أخذت الأحداث منعطفاً سيئاً)، و“Port is a strong wine with a smoky taste.” (بورت مشروب قويّ ذو طعم دخانيّ) بصوت بيل جيتس. وللاستماع إلى أمثلة أخرى، اضغط هنا.
“We frown when events take a bad turn”.
“port is a strong wine with a smoky taste”.
ومع ذلك فإن هناك بعض القيود التي تُكبّل هذا النظام، منها أن الكلام الطبيعي يحتوي على ارتباطات تمتد على مقاييس زمنية أطولَ مدّة، فمثلاً يغيّر البشر نغماتهم الكلامية للإشارة إلى تغيير الموضوع أو تبدّل المزاج في غضون الحكي المُمتد على عشرات الثواني أو الدقائق، أما النظام الذي طورته فيسبوك فيبدو أنه عاجز عن القيام بذلك، على الأقلّ حتى الآن.
لذلك -ومع أن مِل نت (MelNet) قادر على إنتاج عبارات منطوقة مقاربة جداً للكلام الطبيعي بشكل لافت- فالفريق المطور للنظام لم يتوصل بعد إلى جعله ينتج جملاً أو فقرات أطول أو قصصاً كاملة. وهذا هدف لا يبدو أن العلماء سيتوصلون إليه قريباً.
ومع هذا فمن المرجح أن يكون لهذا الإنجاز تأثير كبير على مجال التفاعل بين الإنسان والحاسوب؛ لأن الكثير من المحادثات لا تتكون إلا من عبارات قصيرة فقط، حيث يمكن لعمّال الهاتف أو مراكز دعم العملاء -مثلاً- إنجاز مهامهم باستخدام مجموعة من الجُمل القصيرة إلى حد ما. وهنا يمكن لهذه التقنية أن "تؤتمت" هذه الجُمل بطريقة تجعلها أقرب كثيراً للكلام الإنساني من النُظم المستخدمة حالياً.
ومن ناحية أخرى، لم يتحدث الباحثان فاسكيز ولويس عن التطبيقات المحتملة للنظام الذي طوراه.
وبطبيعة الحال، هناك عدد من المشاكل المحتملة التي تصاحب الآلات القادرة على إنتاج أصوات طبيعية، لا سيما تلك القادرة على محاكاة البشر بصورة دقيقة؛ إذ ليس هناك حاجة لخيال واسع حتى نتصوّر السيناريوهات المتوقعة إذا استُخدمت مثل هذه التقنية في إلحاق الأذى. ولهذا السبب بالذات، يعدّ هذا النظام تقدماً جديداً يحرزه الذكاء الاصطناعي يُثير المزيد من الأسئلة الأخلاقية أكثرَ مما يحاول الإجابة عنها.
المرجع: arxiv.org/abs/1906.01083:
مِل نت (MelNet): نموذج مُولِّد للأصوات على نطاق الترددات