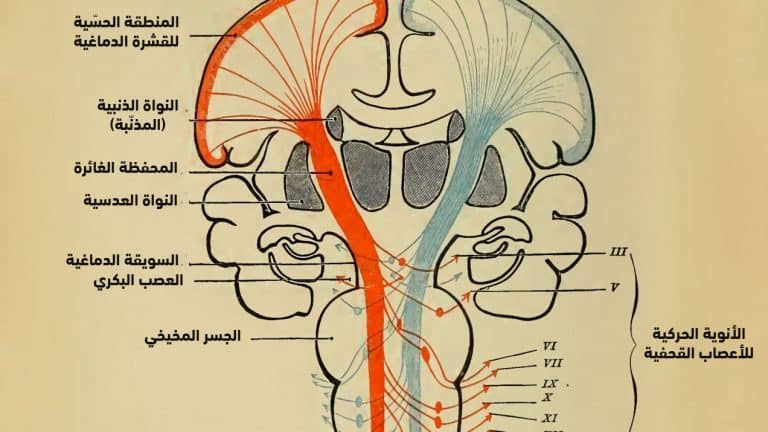
في عام 1951، استخدم مارفن مينسكي -الذي كان طالباً في جامعة هارفارد آنذاك- ملاحظات مأخوذة من سلوك الحيوانات لمحاولة تصميم آلة ذكية. وباعتماده على أعمال عالم الفيزياء إيفان بافلوف -الذي اُشتهر باستخدام الكلاب لتوضيح كيف تقوم الحيوانات بالتعلّم من خلال العقوبات والمكافآت- ابتكر مينسكي حاسوباً يمكنه أن يتعلم بشكل مستمر من خلال تعليم معزّز مماثل لحل متاهة افتراضية.
في ذلك الوقت، لم يكن علماء الأعصاب يعرفون الآليات الدماغية التي تسمح للحيوانات بالتعلّم بهذه الطريقة. لكن مينسكي كان لا يزال بإمكانه محاكاة السلوك بشكل عام، وبالتالي دفع الذكاء الاصطناعي إلى التقدّم. بعد عدة عقود، ومع استمرار التعلّم المعزّز في التطور، فقد ساعد بدوره مجال علم الأعصاب على اكتشاف تلك الآليات، مما أدى إلى تغذية حلقة فعالة من التقدم بين المجالين.
وفي بحث نشر في مجلة نيتشر Nature مؤخراً، قامت شركة ديب مايند DeepMind -الشركة الفرعية المتخصّصة بالذكاء الاصطناعي والتابعة لشركة ألفابت Alphabet- بالاستفادة مرة أخرى من الدروس المأخوذة من التعلم المعزّز لاقتراح نظرية جديدة حول آليات المكافآت داخل أدمغتنا. لم تتمكّن هذه الفرضية المدعومة بالنتائج التجريبية الأولية من أن تحسّن فهمنا للصحة العقلية والتحفيز فحسب، بل يمكنها أيضاً التحقق من الاتجاه الحالي لأبحاث الذكاء الاصطناعي نحو بناء ذكاء عام أكثر شبهاً بالذكاء البشري.
على مستوى عالٍ، يتّبع التعلّم المعزّز الفكرةَ المستمدة من كلاب بافلوف: من الممكن تعليم الأداة إتقان مهام معقدة وجديدة من خلال ردود فعل إيجابية وسلبية فقط. تبدأ الخوارزمية بتعلم مهمة معينة من خلال التنبؤ العشوائي بالإجراء الذي قد يجعلها تكسب مكافأة، ثم تبدأ العمل وتلاحظ المكافأة الحقيقية وتعدّل تنبؤاتها استناداً إلى هامش الخطأ. وبعد الملايين أو حتى المليارات من التجارب، تقترب الأخطاء التنبؤية للخوارزمية من الصفر، وعندها تعرف بدقة الإجراءات التي يجب اتخاذها لزيادة مكافأتها إلى أقصى حدّ وإكمال مهمتها.
وقد اتضح أن نظام المكافآت في الدماغ يعمل إلى حدّ كبير بنفس الطريقة، وهو اكتشاف مستوحى من خوارزميات التعلم المعزز تم التوصل إليه في التسعينيات. عندما يكون الإنسان أو الحيوان على وشك القيام بعمل ما، تقوم عصبونات الدوبامين لديه بالتنبؤ بالمكافأة المتوقعة، وبمجرد استلام المكافأة الفعلية، تقوم بتحرير كمية من الدوبامين تتوافق مع الخطأ التنبؤي. تؤدي المكافأة التي تكون أفضل من المتوقع إلى تحرير شديد للدوبامين، في حين أن المكافأة التي تكون أسوأ من المتوقع تثبّط من إنتاج هذه المادة الكيميائية. بعبارة أخرى، يعمل الدوبامين كإشارة تصحيح، عن طريق إخبار العصبونات بأن تعدّل تنبؤاتها حتى تقترب من الواقع. وتُعرف هذه الظاهرة باسم: خطأ التنبؤ بالمكافأة، وتعمل إلى حد كبير كخوارزمية التعلّم المعزّز.
تعتمد الورقة البحثية الجديدة لشركة ديب مايند على الارتباط الوثيق بين آليات التعلّم الطبيعية والاصطناعية هذه؛ ففي عام 2017، قدّم باحثو الشركة خوارزمية محسّنة للتعلّم المعزّز، والتي طوّرت منذ ذلك الحين أداءً مثيراً للإعجاب في العديد من المهام. وهم يعتقدون الآن أن هذه الطريقة الجديدة يمكنها أن تقدم تفسيراً أكثر دقة لآلية عمل عصبونات الدوبامين في الدماغ.
وعلى وجه التحديد، تغيّر الخوارزمية المحسّنة من الطريقة التي تتوقع بها المكافآت؛ ففي حين أن الطريقة القديمة تقدّر المكافآت على أنها رقم واحد -يقصد به أن يتساوى مع متوسط النتيجة المتوقعة- إلا أن الطريقة الجديدة تمثّلها بدقة أكبر على أنها توزيعية. (الأمر يشبه جهاز البوكر؛ إذ يمكن الفوز أو الخسارة بعد توزيع ما، ولكن لا يمكن الحصول في أي حال من الأحوال على متوسط النتيجة المتوقعة).
يؤدي هذا التعديل إلى فرضية جديدة: هل تتنبأ عصبونات الدوبامين أيضاً بالمكافآت بنفس الطريقة التوزيعية؟
لاختبار هذه النظرية، عقدت شركة ديب مايند شراكة مع إحدى المجموعات في جامعة هارفارد لمراقبة سلوك عصبونات الدوبامين عند الفئران؛ إذ تم إعداد مهمة للفئران ومكافأتها بناءً على رمية النرد، وقياس أنماط إثارة عصبونات الدوبامين لديها طوال الوقت. ووجدوا أن كل عصبون يحرّر كميات مختلفة من الدوبامين، مما يعني أنها تنبأت جميعاً بنتائج مختلفة؛ ففي حين أن بعض الفئران كانت "متفائلة للغاية" وتوقّعت الحصول على مكافآت أعلى من التي حصلت عليها بالفعل، فقد كان البعض الآخر منها "أكثر تشاؤماً" وقلّلت من الواقع. عندما حدّد الباحثون توزيع تلك التنبؤات، فقد كان يتبع توزيع المكافآت الفعلية عن كثب. وتقدّم هذه البيانات أدلة دامغة على أن الدماغ يستخدم بالفعل تنبؤات المكافأة التوزيعية لتعزيز خوارزمية التعلّم الخاصة به.
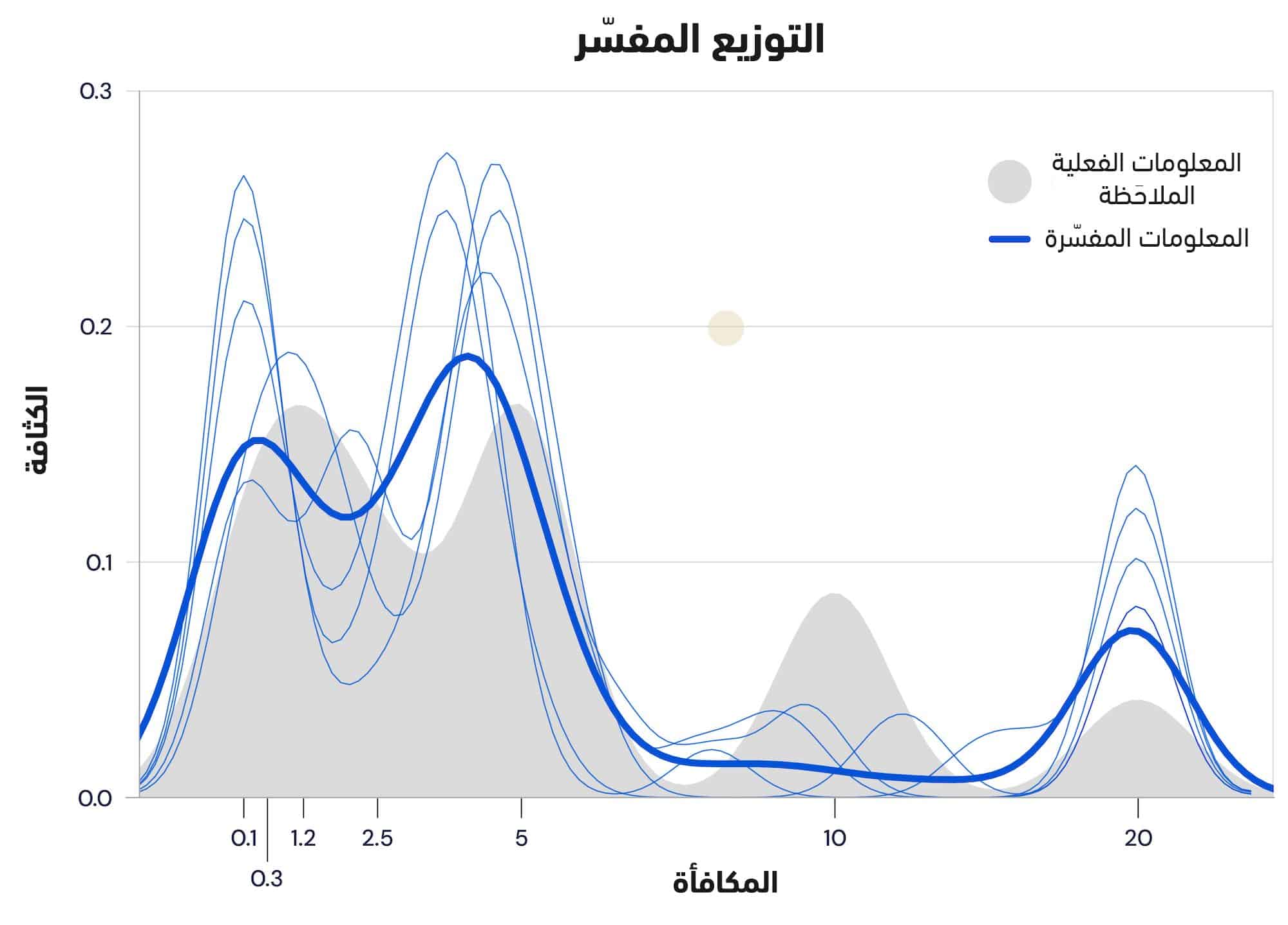
مصدر الصورة الأصلية: شركة ديب مايند | تعديل الصورة: إم آي تي تكنولوجي ريفيو العربية
وكتب وولفرام شولتز -الرائد في سلوك عصبونات الدوبامين والذي لم يشارك في الدراسة- في رسالة إلكترونية: "يعدّ الأمر امتداداً جذاباً لفكرة ترميز الدوبامين لخطأ التنبؤ بالمكافأة. فمن المدهش أن تتبع استجابة الدوبامين البسيطة جداً بشكل تنبؤي أنماطاً بديهية لعمليات التعلّم البيولوجي الأساسية، التي أصبحت الآن إحدى مكونات الذكاء الاصطناعي".
ومن الجدير بالذكر أن لهذه الدراسة آثار على كل من الذكاء الاصطناعي وعلم الأعصاب؛ فهي أولاً تتحقق من صحة التعلّم المعزّز التوزيعي كطريق واعد لإمكانيات أكثر تطوراً في مجال الذكاء الاصطناعي. ويقول مات بوتفينيك، مدير أبحاث علوم الأعصاب في شركة ديب مايند وأحد المؤلفين الرئيسيين للورقة البحثية، خلال مؤتمر صحفي: "إذا كان الدماغ يستخدمه، فهو على الأرجح فكرة جيدة؛ إنه يخبرنا أن هذه طريقة حسابية يمكنها التوسّع في ظروف العالم الحقيقي، ومن شأنه أن يتناسب بشكل جيد مع العمليات الحسابية الأخرى".
ثانياً، يمكن أن يقدّم ذلك تحديثاً مهماً لإحدى النظريات التقليدية في علم الأعصاب حول أنظمة المكافآت في الدماغ، التي بدورها يمكن أن تحسّن فهمنا لكل شيء، من الدافع إلى الصحة العقلية. فعلى سبيل المثال، ما الذي قد يعنيه وجود عصوبات دوبامين "متشائمة" و"متفائلة"؟ وإذا كان الدماغ يستمع بشكل انتقائي إلى نوع واحد فقط، فهل يمكن أن يؤدي ذلك إلى اختلال التوازن الكيميائي وحدوث الاكتئاب؟
بشكل أساسي، ومن خلال إجراء المزيد من عمليات فك التشفير في الدماغ، فإن النتائج تسلّط الضوء أيضاً على مصدر الذكاء البشري. يقول بوتفينيك: "يعطينا الأمر وجهة نظر جديدة حول ما يحدث في أدمغتنا خلال الحياة اليومية".