سارع بعض الباحثين إلى العمل على إيجاد توجهات جديدة، مثل الخوارزميات التي يمكن تدريبها باستخدام بيانات أقل، أو عتاد صلب يستطيع تشغيل هذه الخوارزميات بشكل أسرع. والآن، يقترح باحثو آي بي إم فكرة مختلفة. وتقوم فكرتهم على التخفيف من عدد البتات (أي الوحدان والأصفار، الضرورية لتمثيل البيانات) من 16 بت -وهو المعيار السائد حالياً- إلى 4 بتات وحسب.
يمكن لهذا العمل -الذي سيقدَّم في مؤتمر نيوريبس (NeurIPS)، أضخم مؤتمر سنوي لأبحاث الذكاء الاصطناعي- أن يؤدي إلى زيادة السرعة وتخفيض تكاليف الطاقة المطلوبة لتدريب التعلم العميق بأكثر من 7 أضعاف. ويمكن له أيضاً أن يسمح بتدريب نماذج التعلم الآلي القوية على الهواتف الذكية وغيرها من الأدوات الصغيرة، ما يمكن أن يحسن من الخصوصية بالمساعدة على الاحتفاظ بالبيانات الشخصية على وحدة تخزين محلية. إضافة إلى ذلك، ستصبح هذه العملية متاحة إلى درجة أكبر أمام الباحثين خارج الشركات الضخمة والغنية بالموارد التقنية.
كيف تعمل البتات
من المرجح أنك قد سمعت بأن الحواسيب تخزن الأشياء على شكل أصفار (0) ووحدان (1). تُعرف هذه الوحدات الأساسية للمعلومات باسم البتات. فعندما يكون البت في حالة “تشغيل” يتوافق مع القيمة 1، وعندما يكون في حالة “إطفاء” يتحول إلى 0، وبالتالي يستطيع كل بت أن يخزن معلومتين فقط.
ولكن إذا جمعنا عدة بتات معاً، فإن كمية المعلومات التي يمكن أن نرمزها تتضاعف بشكل سريع (بتسارع أُسِّي)؛ حيث يمكن لاثنين من البتات أن يمثلا 4 معلومات، لأنه توجد أربعة تراكيب ممكنة، أي 2^2. وهذه التراكيب هي: 00، 01، 10، 11. وتستطيع أربعة بتات أن تمثل 2^4=16 معلومة. أما ثمانية بتات فتستطيع أن تمثل 2^8=256 معلومة. وهكذا دواليك.
تستطيع التراكيب الصحيحة من البتات أن تمثل أنواعاً من البيانات مثل الأرقام والأحرف والألوان، أو أنواعاً من العمليات مثل الجمع والطرح والمقارنة. وتعمل معظم الحواسيب حالياً باستخدام 32 بت أو 64 بت. ولكن هذا لا يعني أن قدرة الحاسوب محدودة بترميز 2^32 أو 2^64 معلومة (وإلا فسوف يكون في هذه الحالة حاسوباً ضعيفاً للغاية)، بل يعني أنه يمكن استخدام هذه الدرجة من التعقيد لترميز كل جزء من البيانات أو كل عملية إفرادية.
التعلم العميق بأربعة بتات
ولكن ماذا يعني التدريب بأربعة بتات؟ في البداية، يعني هذا وجود حاسوب يعمل بأربعة بتات، وبالتالي 4 بتات من التعقيد. ويمكن أن نفكر في الموضوع بالطريقة التالية: كل رقم نستخدمه خلال عملية التدريب يجب أن يكون واحداً من 16 رقماً صحيحاً تتراوح من 8- إلى 7 (من العدد السالب [8-] إلى العدد الموجب [7+] على محور الأعداد الصحيحة)، لأنها الأرقام الوحيدة التي يستطيع الحاسوب تمثيلها. وهذا ينطبق على نقاط البيانات التي نقوم بتلقيمها إلى الشبكة العصبونية، والأرقام التي نستخدمها لتمثيل الشبكة العصبونية، والأرقام الوسيطة التي نحتاج إلى تخزينها أثناء التدريب.
إذن، كيف يمكن أن نحقق هذا؟ لنفكر أولاً في بيانات التدريب. تخيل وجود عدد كبير من الصور بالأبيض والأسود. الخطوة الأولى: يجب أن نحول هذه الصور إلى أرقام، بحيث يستطيع الحاسوب استيعابها. ويمكن أن نقوم بهذا عبر تمثيل كل بيكسل من حيث قيم التدرجات الرمادية، أي 0 للون الأسود، 1 للون الأبيض، أما الكسور العشرية الواقعة بين هذين الرقمين فهي تمثل تدرجات الرمادي. الآن، أصبحت الصورة عبارة عن قائمة من الأرقام التي تتراوح بين الصفر والواحد. ولكن، وفي هذا العالم المكون من 4 بتات، يجب أن تتراوح هذه الأرقام بين 8- و 7. ولهذا، يجب أن نستخدم حيلة تقوم على تقييس قائمة الأرقام بصورة خطية (linear scale)، بحيث يتحول الصفر إلى 8-، ويتحول الواحد إلى 7، أما الأرقام الأخرى فهي الأعداد الصحيحة المتبقية في هذا المجال. وبالتالي:
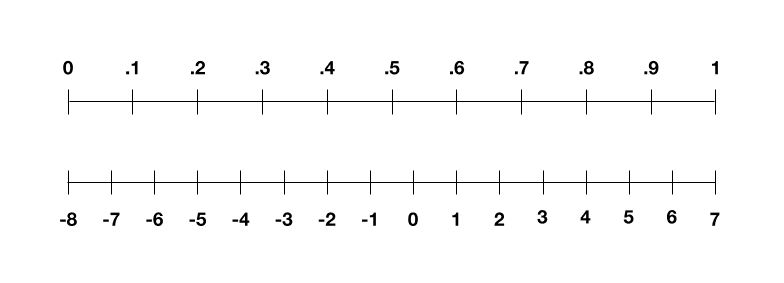
ولكن هذه العملية ليست مثالية؛ فإذا بدأنا بالرقم 0.3 على سبيل المثال، سنصل إلى رقم مقيّس بقيمة 3.5-. ولكن بتّاتنا الأربعة تستطيع تمثيل مجموعة من الأعداد الصحيحة وحسب، ولهذا يجب تدوير 3.5- إلى 4-. يعني هذا أننا سنخسر بعض التدرجات الرمادية في الصورة، وبتعبير آخر، سنخسر بعض الدقة. يمكنك أن ترى ما الذي سيحدث في الصورة أدناه.
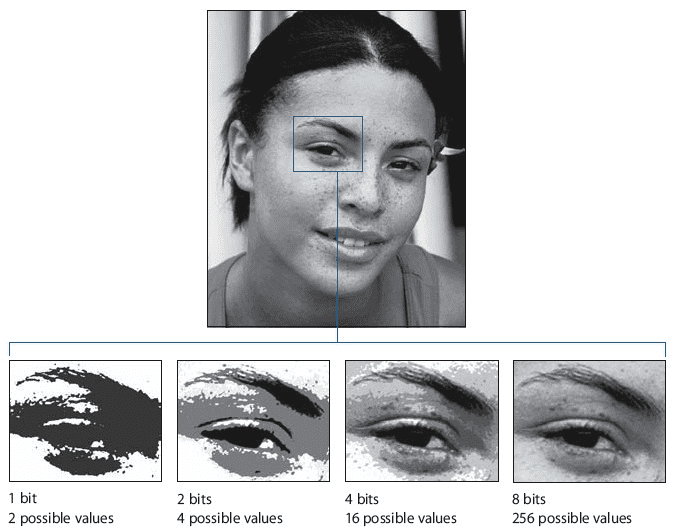
قد تكون هذه الحيلة صالحة إلى حد ما لبيانات التدريب. ولكن عند تطبيقها ثانية على الشبكة العصبونية نفسها، ستصبح الأمور أكثر تعقيداً.
غالباً ما نرى الشبكات العصبونية ممثلة على شكل عقد ووصلات، كما في الصورة أعلاه. ولكن بالنسبة للحاسوب، فإن هذه العناصر تتحول أيضاً إلى سلسلة من الأرقام. تحمل كل عقدة قيمة تسمى بقيمة التفعيل، وتتراوح عادة بين الصفر والواحد، وكل وصلة لديها وزن، يتراوح عادة بين 1- و1.
يمكن أن نقوم بتقييس هذه الأرقام بنفس الطريقة المذكورة سابقاً، ولكن قيم التفعيل والأوزان تتغير مع كل جولة من التدريب. وعلى سبيل المثال، فإن قيم التفعيل تتراوح بين 0.2 و0.9 في إحدى الجولات، وبين 0.1 و0.7 في جولة أخرى؛ ولهذا فكرت مجموعة آي بي إم في حيلة أخرى عام 2018، تقوم على إعادة تقييس هذه المجالات حتى تمتد بين 8- و 7 في كل جولة، كما يبين الشكل أدناه، ما يؤدي عملياً إلى تجنب فقدان الكثير من الدقة.
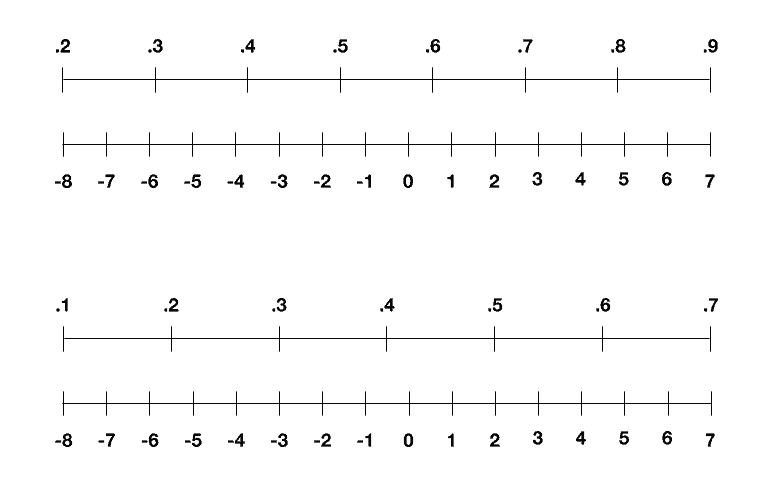
وبقيت أمامنا مسألة واحدة أخيرة، وهي كيفية تمثيل القيم الوسيطة التي تظهر أثناء التدريب باستخدام 4 بتات. تكمن صعوبة هذه المسألة في أن هذه الأرقام تمتد على عدة مراتب، وذلك خلافاً للأرقام التي كنا نستخدمها في الصور والأوزان وقيم التفعيل. فقد تكون صغيرة مثل 0.001 أو كبيرة مثل 1,000. وبالتالي فإن محاولة تقييسها خطياً بين 8- و 7 ستؤدي إلى فقدان كل الدقة الموجودة في الجهة الصغرى من المقياس.
سيؤدي التقييس الخطي للأرقام التي تمتد على عدة مراتب إلى فقدان كل الدقة في الجهة الصغرى من المقياس. كما يبدو هنا، فإن الأرقام أصغر من 100 سيتم تقييسها إما إلى 8- أو 7-. وسيؤدي فقدان الدقة هنا إلى إضعاف الأداء النهائي لنموذج الذكاء الاصطناعي.
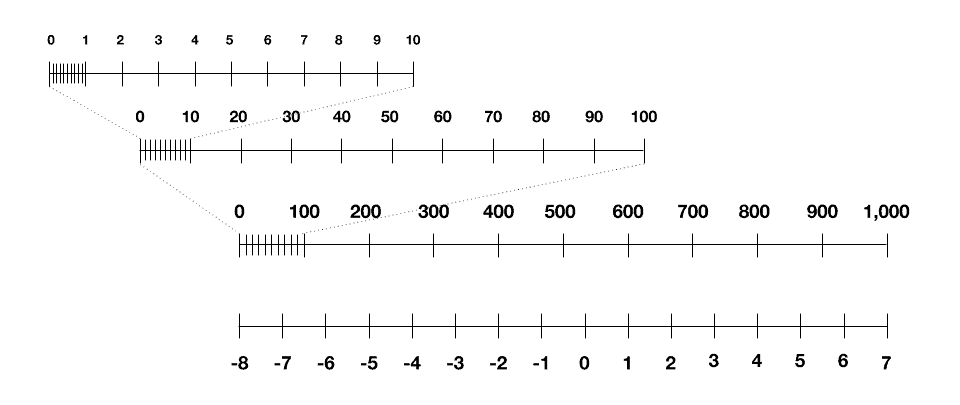
وبعد سنتين من البحث، تمكن الباحثون أخيراً من حل اللغز: فباستعارة فكرة موجودة مسبقاً، تمكنوا من تقييس هذه الأرقام الوسيطة لوغاريتمياً. ولشرح معنى هذا المصطلح، يمكن أن تنظر في الأسفل إلى المقياس اللوغاريتمي، الذي قد يكون مألوفاً لديك بأنه يسمى “ذو الأساس 10″، باستخدام 4 بتات من التعقيد وحسب. (ولكن الباحثين استخدموا بدلاً من 10 الأساس 4، فقد أظهرت التجارب أن هذه القيمة تحقق نتائج أفضل) يمكنك أن ترى بسهولة كيف يسمح هذا المقياس بترميز الأرقام الصغيرة والكبيرة في نفس الوقت ضمن القيود المفروضة على البتات.
والآن، وبعد أن اكتملت جميع العناصر، يبين البحث الجديد كيف يمكن استخدامها معاً. فقد أجرى باحثو آي بي إم عدة تجارب قاموا فيها بمحاكاة التدريب بأربع بتات لمجموعة من نماذج التعلم العميق في الرؤية الحاسوبية، والتعرف على الكلام، ومعالجة اللغة الطبيعية. وتبين النتائج انخفاضاً محدوداً للدقة في الأداء الإجمالي للنموذج، مقارنة مع التعلم العميق باستخدام 16 بت. تبين للباحثين أيضاً أن العملية أصبحت أسرع بسبع مرات، وأكثر فعالية في استهلاك الطاقة بسبع مرات أيضاً.
العمل المستقبلي
ما زالت هناك عدة خطوات إضافية قبل أن يدخل التعلم العميق باستخدام 4 بتات حيز التطبيق الفعلي؛ حيث إن البحث يقوم فقط على محاكاة نتائج هذا النوع من التدريب. أما في العالم الحقيقي، فإن تنفيذه سيتطلب بناء عتاد صلب جديد اعتماداً على 4 بتات. في 2019، أطلقت آي بي إم مركز العتاد الصلب للذكاء الاصطناعي، وذلك من أجل تسريع عملية تطوير وإنتاج هذا النوع من التجهيزات. ويقول كايلاش جوبالاكريشنان، وهو زميل في آي بي إم والمدير الرئيسي الذي يشرف على هذا العمل، إنه يتوقع أن يكون العتاد الصلب بأربع بتات جاهزاً للتعلم العميق في غضون 3 إلى 4 سنوات.
وبالنسبة لبوريس مورمان، وهو أستاذ في جامعة ستانفورد ولم يشارك في هذا العمل، فقد وصف النتائج بأنها تثير الحماسة. ويقول: “إن هذا التطور يفتح الباب أمام التدريب في بيئات محدودة الموارد”. لن يؤدي هذا بالضرورة إلى فتح المجال أمام تطبيقات جديدة، ولكنه سيجعل من التطبيقات الموجودة مسبقاً أكثر سرعة وأقل استهلاكاً للكهرباء “بفارق كبير”. وعلى سبيل المثال، فقد سعت أبل وجوجل -وبشكل متزايد- إلى نقل عملية تدريب نماذجهما، مثل أنظمة تحويل الكلام إلى نص والتصحيح التلقائي، من السحابة الإلكترونية إلى هواتف المستخدمين. وهو ما سيحافظ على خصوصية المستخدمين عن طريق الاحتفاظ بالبيانات على هواتفهم، ويحسن في نفس الوقت من قدرات الذكاء الاصطناعي لهذه الأجهزة.
ولكن مورمان يلحظ أيضاً أننا ما زلنا في حاجة إلى المزيد من العمل لتأكيد صحة هذا البحث؛ ففي 2016، قامت مجموعته بنشر بحث حول التدريب بخمسة بتات. ولكن هذه الطريقة لم تحافظ على فعاليتها مع مرور السنوات. ويقول: “لقد تداعت طريقتنا البسيطة لأن الشبكات العصبونية أصبحت أكثر حساسية بكثير؛ ولهذا ليس من الواضح ما إذا كانت طريقة كهذه قادرة على الصمود مع مرور الزمن”.
ولكنه يضيف قائلاً إن البحث “سيحفز الآخرين على دراسة هذه المسألة بعناية وسيحفز ظهور أفكار جديدة، وهو تطور رائع بحد ذاته”.